
AI is al geruime tijd aanwezig. Gebruiksscenario’s waren soms niet haalbaar vanwege de complexiteit van de implementatie of beperkingen binnen AI of rekenkracht. Elastic-technologie maakt het gemakkelijker om te profiteren van de voordelen van AI. Elastic maakt het minder ingewikkeld voor ontwikkelaars om semantisch zoeken, beeldzoeken en meer te implementeren. Het bewijs van de pudding zit in het eten. Dat is de reden waarom we een experiment hebben uitgevoerd en beeldgelijkenis hebben ontwikkeld in Elastic. In deze blog zullen we praten over het hoe en vooral de indrukwekkende resultaten die zijn behaald uit het experiment.
Dit artikel onderzoekt de toepassing van Elastic in zoekopdrachten naar afbeeldingssimilariteit, met de focus op iconen zoals het recycle-symbool en de Europese letter ‘E’. Er worden specifieke experimenten uitgevoerd met deze symbolen, naast discussies over technische uitdagingen en oplossingen. Dit artikel benadrukt met name de veelbelovende resultaten die zijn behaald met het recycle-icoon en de Europese letter ‘E’. Het potentieel van beeldsimiliteitstechnologie voor toekomstige projecten is veelbelovend, waarbij de eenvoud en effectiviteit ervan in het insluiten van afbeeldingen en tekst voor zoekdoeleinden worden benadrukt.
Fun fact: De implementatie van dit experiment met de Elastic-stack kostte minder dan een dag, inclusief de reparaties en aanpassingen die nodig waren tijdens het ontwikkelingsproces.
We beschikken over een dataset van precies 47 afbeeldingen:

Bij het zoeken naar een afbeelding door “European E” in te typen, ontvangen we Europese E’s als de eerste resultaten, wat goed is.

In plaats van teksttermen te gebruiken om afbeeldingen te zoeken, hebben we ook een van deze “European E” symbolen gebruikt om te zoeken door op “Vergelijkbare afbeeldingen zoeken” te klikken. Dit leverde ook de verwachte vergelijkbare afbeeldingen als zoekresultaten op.
Groen recycle-symbool

2) de technische route op: hoe we resultaten hebben behaald
Het begin
We zijn onze verkenning gestart op basis van deze informatieve blogpost van Elastic.
We hebben nauwgezet de instructies gevolgd die zijn uiteengezet in de blogpost van Elastic en het GitHub-repository. Na grondige bestudering van het README.md-bestand zijn we overgegaan tot het klonen van het repository en hebben we het vereiste model van Hugging Face geïntegreerd in onze cloud-instantie met behulp van Elastic’s eland van GitHub. Houd er rekening mee dat dit model niet per se gebruikt hoeft te worden. Andere modellen kunnen ook worden gebruikt, maar dan moet de backend worden aangepast.
Het aanpassen van de code
Tijdens het proces stuitten we op verouderde pakketten. We hebben snel het requirements.txt-bestand aangepast om compatibiliteit en een soepele installatie te garanderen. Daarnaast hebben we beperkingen in pixels voor afbeeldingen aangepakt en instellingen fijngesteld voor optimale prestaties. Hieronder staat het verbeterde requirements.txt-bestand:
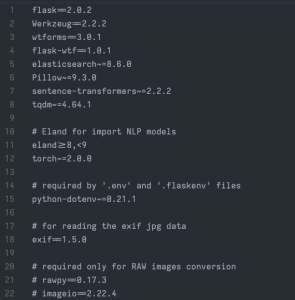
Na deze aanpassingen verliep het pip installatieproces probleemloos. Bovendien werd het ‘.env-bestand’ bijgewerkt met de benodigde referenties voor onze cloud-instantie. Echter, bij het proberen om afbeeldingsembeddings te genereren en deze in te voeren, werd een daaropvolgend probleem ondervonden. Deze uitdaging, waar binnenkort nader op zal worden ingegaan, ontstond door een oversaturatie van pixels binnen onze afbeeldingen. Om dit aan te pakken, volstond een eenvoudige regel toevoeging onder de imports sectie van het bestand create-image-embeddings.py. Let op: de code zorgt ervoor dat er geen maximumlimiet is voor het aantal pixels in een afbeelding, dus let op hoe je dit gebruikt (decompression bomb):
De afbeeldingen invoeren
Om te beginnen waren afbeeldingen nodig. Voor deze test werden afbeeldingen gebruikt die gemakkelijk te vinden zijn via Google: een recycle-pictogram en de letter ‘E’ van Europa. Alle afbeeldingsbestandstypen werden geconverteerd naar JPG, omdat dit het beste bestandstype leek te zijn om te gebruiken voor dit geval. Om de afbeeldingen zelf in te voeren, moest het bijgeleverde Python-script worden gebruikt, dat zich bevindt onder `image_embeddings/create-image-embeddings.py`
Tot slot werden alle embeddings ingevoerd, wat er ongeveer zo uitzag:

De embedding heeft 512 dimensies. Houd er rekening mee dat deze afbeelding door het clip-ViT-B-32-model is gegaan. Dit is een gratis openbaar model en is voldoende voor ons gebruiksscenario. De interface heeft een zoekvak, dat wanneer ingediend tekst naar Elastic stuurt die door het model gaat (clip-ViT-B-32-multilingual-v1) dat is geïmporteerd met Elastic eland. Dit gebeurt op de achtergrond (Flask Backend) en daarom is er geen noodzaak om dat in deze demotoepassing te bekijken, noch zullen we naar de Flask-backend kijken in deze blogpost. De interface heeft een veld voor het uploaden van afbeeldingen. Dit kan worden gebruikt om afbeeldingen te uploaden en te zoeken naar andere afbeeldingen die vergelijkbaar zijn met de geüploade afbeelding.
Grootte van afbeeldingen
Zoals hierboven vermeld, bestaat onze dataset uit 47 afbeeldingen. Deze afbeeldingen hebben samen een grootte van ongeveer 3,6 MB. Wanneer we kijken naar de index met de ingebedde waarden, is de grootte 469,9 kB.
Grootte van tekst
We vergeleken de grootte van embeddings voor afbeeldingen met embeddings voor tekst. We gebruikten een dataset met ongeveer 8000 documenten en een totale grootte van 17,7 MB. Elk document bevat slechts een paar regels tekst. Bij het invoeren van deze gegevens voor ‘tekst zoeken’ in een index, neemt de index 36,3 MB in beslag. Bij het invoeren voor semantisch zoeken, met behulp van het E5-model, neemt de index 119,8 MB in beslag. In het geval dat beide indexes worden gebruikt, bijvoorbeeld om RRF (Reciprocal Rank Fusion) te gebruiken, is de totale indexopslag 156,1 MB.
Waarom nam de grootte af voor de afbeeldingen maar nam deze toe voor tekst?
Dit komt door de dimensies en het aantal documenten. De afbeeldingenindex hoefde slechts 47 documenten bij te houden, terwijl de tekstdataset-index ongeveer 8000 documenten moest bijhouden. De afbeeldingendataset had een grootte van 9,99 kB per document, terwijl de tekstindex ongeveer 14,97 kB per document had. Dit is relatief dicht bij de afbeeldingenindex. Als we naar de totale vectorafmetingen kijken, heeft de afbeeldingenindex 512 dimensies. De tekstindex heeft echter ongeveer 768 dimensies; zowel de ingesloten velden voor titel als overzicht hebben elk 384 dimensies. Dus uiteindelijk hangt het af van hoeveel dimensies er worden gebruikt. Als we slechts één veld zouden gebruiken om in te sluiten, zou de grootte aanzienlijk afnemen, hetzelfde kan gezegd worden voor de afbeeldingenindex. Als we een ander model zouden gebruiken dat meer dimensies genereert, zou de grootte aanzienlijk toenemen.
Als we nog dieper ingaan op de details, heeft de afbeeldingenindex ongeveer 19,51 bytes per dimensie, terwijl de tekstindex 19,49 bytes per dimensie heeft. Zoals hier te zien is, zijn ze ongeveer hetzelfde. Dus volgens deze logica zouden we 19,5 bytes kunnen nemen als gemiddelde voor elke vector dimensie. Houd er rekening mee dat dit dichte vectoren zijn, geen ijle vectoren.
We waren zeer onder de indruk van de functionaliteit van ‘Image Similarity Search’, waarbij we met name de eenvoudige werkwijze om een model van Huggingface te verkrijgen, zowel afbeeldingen als tekst in te sluiten, en zoekopdrachten te initiëren, zeer waardeerden.
Elk Factory is de Elastic partner om uw Elastic-stack te implementeren. We streven altijd naar een win-winsituatie! Samen zullen we verkennen hoe dit platform uw bedrijf efficiënter kan maken, zodat u kunt profiteren terwijl wij een tevreden klant worden!
Leer ons kennen, of neem vrijblijvend contact met ons op.