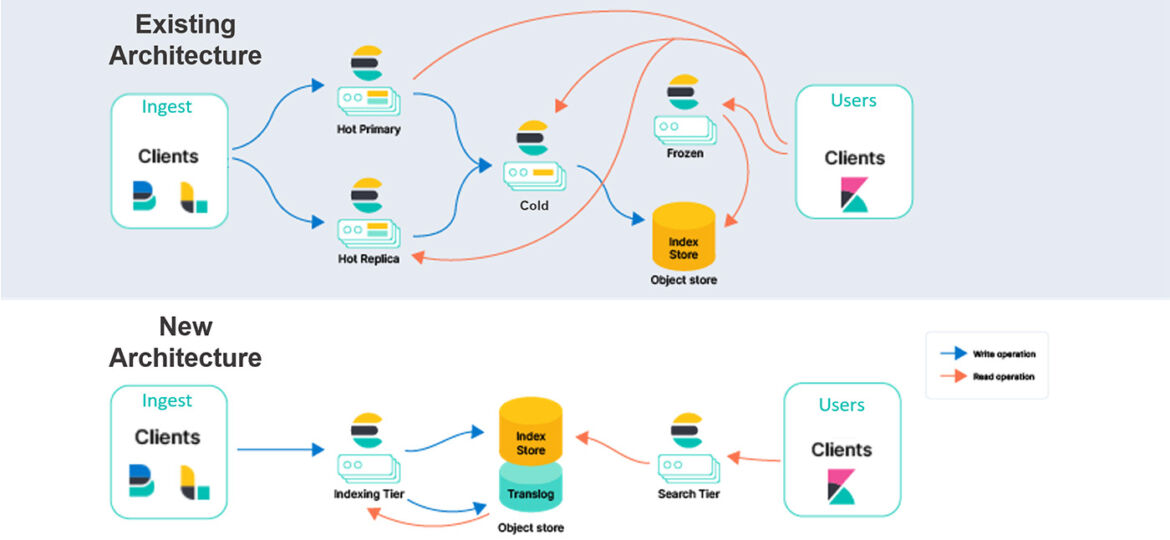
STATELESS ARCHITECTURE
Since the beginning, Elasticsearch has always kept its persistence layer like data and cluster state stored on local disks while also making sure to replicate it across machines or data centers to provide redundancy. With the change to stateless, the plan is to move this local persistence to Cloud object stores like AWS S3, Azure Blob Store, or GCP Cloud Storage, where replication happens automatically.
Elasticsearch has two main workloads; indexing and search. Moving to a stateless architecture could mean hosting these workloads on separate hardware. This comes with significant advantages. Workloads would not impact each other and could be scaled independently in terms of hardware resources. Lastly, hosting data in separate object stores reduces indexing costs and makes it easier to tune search performance.
This all looks and sounds very promising and we can’t wait to get started with the new and improved Elasticsearch.
https://www.elastic.co/blog/stateless-your-new-state-of-find-with-elasticsearch