

IMAGE SIMILARITY SEARCH WITH ELASTIC
AI has been around for some time. Use cases were sometimes not achievable due to the complexity of the implementation or limits within AI or computing power. Elastic technology makes it easier to enjoy the benefits of AI. Elastic makes it less complicated for developers to implement semantic search, image search and more. The proof of the pudding is in the eating. That’s the reason why we did an experiment and developed image similarity in Elastic. In this blog we will talk about the how and most importantly the impressive results achieved from the experiment.
THE CONTEXT
This article explores Elastic’s application in image similarity searches, focusing on icons like the recycle symbol and the European letter ‘E’. Specific experiments with these symbols are conducted, alongside discussions on technical challenges and solutions. This article particularly highlights the promising results achieved with the recycle icon and the European letter ‘E’. The potential of Image similarity technology for future projects is promising, underlining its simplicity and effectiveness in embedding images and text for searching purposes.
Fun fact: The implementation of this experiment with the Elastic stack took less than a day, including the repairments and adjustments that were needed during the development process.
First we will explain the results in this article, afterwards we will provide the technical details how we realized the image similarity search. To conclude will provide some insights with respect to sizing.
1) IMAGE SIMILARITY – SEARCH RESULTS
We have a dataset of 47 images to be precise:

When searching for an image, typing “European E” we receive European E’s as the first results, which is good.
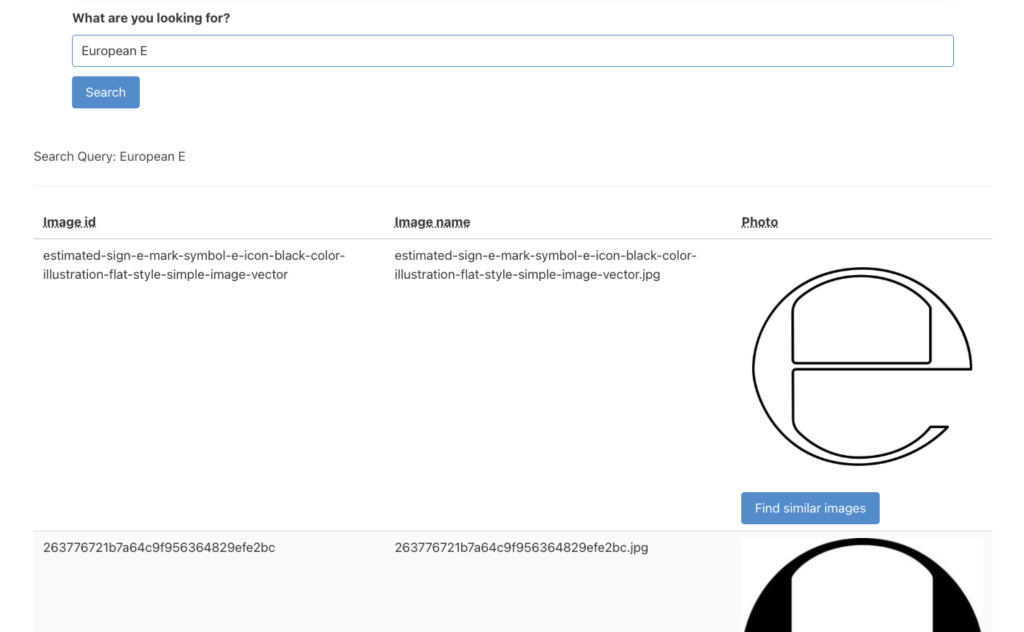
Instead of using text terms to search for images, we also used one of these “European E” symbols to search by clicking “Find similar images”. This also provided the expected similar images as search results.
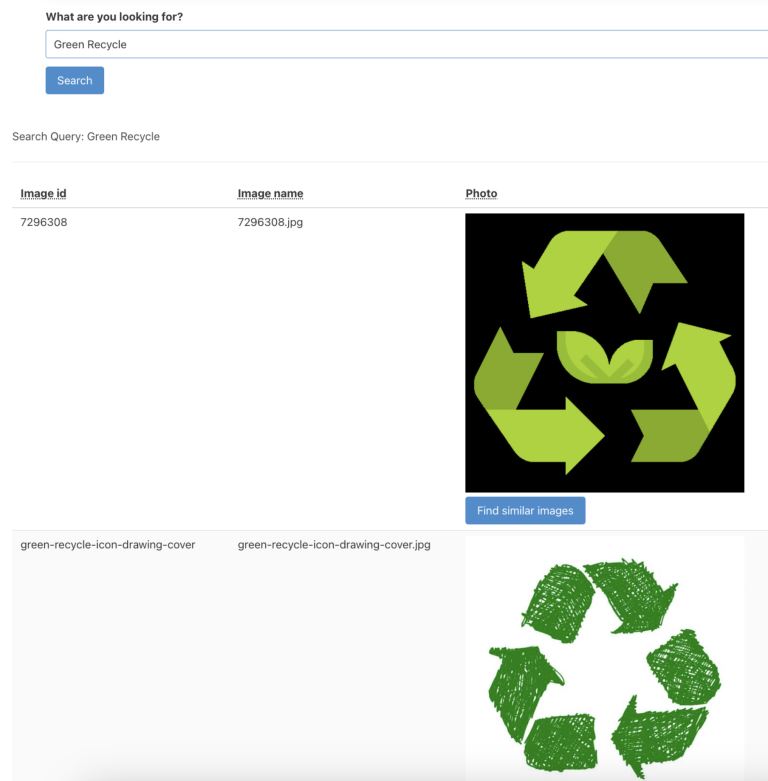
Green recycle symbol
In our dataset, we have several recycle symbols of which a few are green. We did a test searching for “green recycle”. This did in fact only return our green recycle icons in the dataset, which is a great result:
2) THE TECHNICAL JOURNEY: HOW WE ACHIEVED RESULTS
The start
We started our exploration based on this informative blog post from Elastic.
We meticulously followed the instructions outlined in Elastic’s blog post and GitHub repository. After thorough perusal of the README.md file, we proceeded to clone the repository and integrated the required model from Hugging Face into our cloud instance using Elastic’s eland from Github. Keep in mind that this model does not need to be used. Other models can be used as well however then the backend would need to be modified.
Modifying the code
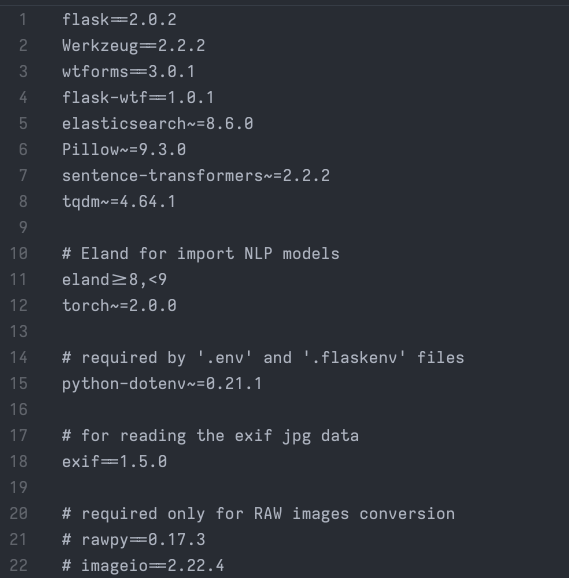
Encountering outdated packages during the process, we swiftly modified the requirements.txt file, ensuring compatibility and smooth installation. Additionally, we addressed image pixel limitations and fine-tuned settings for optimal performance. Below illustrates the improved requirements.txt file:
Following these adjustments, the pip install process proceeded seamlessly. Additionally, the ‘.env file’ was updated with the necessary credentials for our cloud instance. However, while attempting to generate image embeddings and ingest them, a subsequent issue was encountered. This challenge, which will be elaborated upon shortly, came from an oversaturation of pixels within our images. To address this, a simple line addition under the imports section of the create-image-embeddings.py file sufficed. Note: The code makes sure there is no maximum image pixels limit so watch out with how you use this (Decompression bomb):
Image.MAX_IMAGE_PIXELS = None
Ingesting images
To start, images were needed. For this test images were used that can be easily found using Google: a recycle icon and the ‘European E letter’. All the image file types were converted to JPG as this seemed to be the best file type to use for this case. To ingest the images itself, the provided python script had to be used which is located under `image_embeddings/create-image-embeddings.py`
Finally, all the embeddings were ingested which looked something like this:

The embedding has 512 dimensions. Keep in mind that this image went through the clip-ViT-B-32 model. This is a free public model and is sufficient for our use case. The interface has a search box, which when submitted sends text to elastic which goes through the model (clip-ViT-B-32-multilingual-v1) that was imported with Elastic eland. This happens in the background (Flask Backend) and therefore, there is no need to look at that in this demo application, nor will we look at the Flask backend in this blog post. The interface has an image upload field. This can be used to upload images and search for other images that are similar to the uploaded one.
3) SIZING
Size of Images
As mentioned above our dataset consists of 47 images. These Images have a combined size of around 3.6Mb. When looking at the index with the embedded values, the size is 469.9Kb.
Size of Text
We compared the sizing of embeddings for images with embeddings for text. We used a dataset containing about 8000 documents and having a size of 17.7Mb in total. Each document has only a few lines of text. When ingesting this data for ‘text search’ into an index, the index takes 36.3Mb. When ingesting for semantic search, using the E5 model the index takes 119.8Mb. In case both indexes are used for example to use RRF (Reciprocal Rank Fusion), the total index storage is 156.1Mb.
Why did the size decrease for the images but increase for Text
This is because of the dimensions and number of documents. The images index only had to keep 47 documents while the Text dataset’s index had to keep around 8000 documents. The Images dataset had the size of 9,99Kb per document While the Text index had around 14.97Kb per document. Which is relatively close to the Images index. If we take a look at the total vector dimensions, the Images index has 512 dimensions. However the Text index has around 768 dimensions, both the title and overview embedded fields have 384 dimensions. So after all it depends on how much dimensions are being used, if we used only one field to embed the size would greatly decrease, same can be said for the images index, if we used another model that generates more dimensions the size would greatly increase.
If we go into even deeper detail, the images index has about 19.51bytes per dimension while the text index has 19.49bytes per dimension. As can be seen here they are about the same. So by this logic we could take 19.5b as average for each vector dimension. Keep in mind these are dense vectors, not sparse vectors.
4) CONCLUSION
We were highly impressed with the ‘Image Similarity Search’ functionality, particularly appreciating the straightforward process of obtaining a model from Huggingface, embedding both images and text, and initiating searches.
ELK FACTORY – ELITE ELASTIC PARTNER
Elk Factory is the Elastic partner to implement your Elastic stack. We always strive for a win-win! Together, we’ll explore how this platform can make your business more efficient, so you can benefit while we gain a satisfied customer!